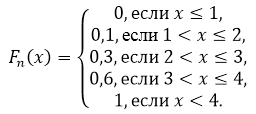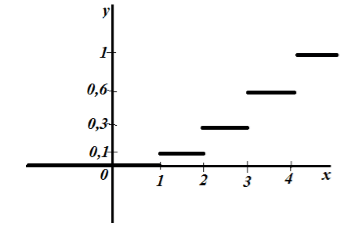Empirijska funkcija distribucije. Empirijska funkcija distribucije, svojstva Primjer empirijske funkcije distribucije
Predavanje 13. Koncept statističkih procjena slučajnih varijabli
Neka je poznata statistička distribucija učestalosti kvantitativnog obilježja X. Označimo s brojem opažanja u kojima je uočena vrijednost obilježja manja od x, a s n ukupni broj opažanja. Očito, relativna učestalost događaja X< x равна и является функцией x. Так как эта функция находится эмпирическим (опытным) путем, то ее называют эмпирической.
Empirijska funkcija distribucije(funkcija distribucije uzorkovanja) je funkcija koja za svaku vrijednost x određuje relativnu učestalost događaja X< x. Таким образом, по определению ,где - число вариант, меньших x, n – объем выборки.
Za razliku od empirijske funkcije raspodjele uzorka, funkcija raspodjele populacije tzv teorijska funkcija distribucije. Razlika između ovih funkcija je u tome što teorijska funkcija određuje vjerojatnost događaji X< x, тогда как эмпирическая – relativna frekvencija isti događaj.
Kako n raste, relativna učestalost događaja X< x, т.е. стремится по вероятности к вероятности этого события. Иными словами
Svojstva empirijske funkcije distribucije:
1) Vrijednosti empirijske funkcije pripadaju segmentu
2) - neopadajuća funkcija
3) Ako je najmanja opcija, tada = 0 za , ako je najveća opcija, tada = 1 za .
Empirijska funkcija distribucije uzorka služi za procjenu teorijske funkcije distribucije populacije.
Primjer. Konstruirajmo empirijsku funkciju na temelju distribucije uzorka:
| Mogućnosti | |||
| Frekvencije |
Nađimo veličinu uzorka: 12+18+30=60. Najmanja opcija je 2, dakle =0 za x £ 2. Vrijednost x<6, т.е. , наблюдалось 12 раз, следовательно, =12/60=0,2 при 2< x £6. Аналогично, значения X < 10, т.е. и наблюдались 12+18=30 раз, поэтому =30/60 =0,5 при 6< x £10. Так как x=10 – наибольшая варианта, то =1 при x>10. Dakle, željena empirijska funkcija ima oblik:
Najvažnija svojstva statističkih procjena
Neka je potrebno proučiti neku kvantitativnu karakteristiku opće populacije. Pretpostavimo da je iz teorijskih razmatranja to bilo moguće utvrditi koji točno raspodjela ima predznak i potrebno je ocijeniti parametre kojima je ona određena. Na primjer, ako je karakteristika koja se proučava normalno raspoređena u populaciji, tada je potrebno procijeniti matematičko očekivanje i standardnu devijaciju; ako karakteristika ima Poissonovu distribuciju, tada je potrebno procijeniti parametar l.
Obično su dostupni samo uzorci podataka, na primjer, vrijednosti kvantitativne karakteristike dobivene kao rezultat n neovisnih opažanja. Promatrajući kao nezavisne slučajne varijable možemo reći da pronaći statističku procjenu nepoznatog parametra teorijske distribucije znači pronaći funkciju promatranih slučajnih varijabli koja daje približnu vrijednost procijenjenog parametra. Na primjer, za procjenu matematičkog očekivanja normalne distribucije, ulogu funkcije ima aritmetička sredina
Kako bi statističke procjene dale točnu aproksimaciju procijenjenih parametara, one moraju zadovoljiti određene zahtjeve, među kojima su najvažniji zahtjevi neraseljena I solventnost procjene.
Neka je statistička procjena nepoznatog parametra teorijske distribucije. Neka se procjena nađe iz uzorka veličine n. Ponovimo eksperiment, tj. izdvojimo drugi uzorak iste veličine iz opće populacije i na temelju njegovih podataka dobijemo drugačiju procjenu. Ponavljajući pokus više puta, dobivamo različite brojeve. Rezultat se može promatrati kao slučajna varijabla, a brojevi kao njezine moguće vrijednosti.
Ako procjena daje približnu vrijednost u izobilju, tj. svaki broj je veći od stvarne vrijednosti, i kao posljedica toga, matematičko očekivanje (prosječna vrijednost) slučajne varijable je veće od:. Isto tako, ako daje procjenu s nedostatkom, To .
Dakle, korištenje statističke procjene, čije matematičko očekivanje nije jednako procijenjenom parametru, dovelo bi do sustavnih (istog predznaka) pogrešaka. Ako je, naprotiv, to jamči protiv sustavnih pogrešaka.
Nepristran naziva se statistička procjena, čije je matematičko očekivanje jednako procijenjenom parametru za bilo koju veličinu uzorka.
Raseljeni naziva se procjena koja ne zadovoljava ovaj uvjet.
Nepristranost procjene još ne jamči dobru aproksimaciju za procijenjeni parametar, jer moguće vrijednosti mogu biti vrlo raštrkani oko svoje prosječne vrijednosti, tj. varijanca može biti značajna. U tom slučaju, procjena dobivena iz podataka jednog uzorka, na primjer, može se pokazati značajno udaljenom od prosječne vrijednosti, a time i od parametra koji se procjenjuje.
Učinkovito je statistička procjena koja, za danu veličinu uzorka n, ima najmanja moguća varijanca .
Kada se razmatraju veliki uzorci, potrebne su statističke procjene solventnost .
Imućni naziva se statistička procjena, koja, kako n®¥ teži u vjerojatnosti procijenjenom parametru. Na primjer, ako varijanca nepristrane procjene teži nuli kao n®¥, tada se takva procjena pokazuje dosljednom.
Kao što je poznato, zakon raspodjele slučajne varijable može se odrediti na različite načine. Diskretna slučajna varijabla može se specificirati pomoću niza distribucije ili integralne funkcije, a kontinuirana slučajna varijabla može se specificirati pomoću integrala ili diferencijalne funkcije. Razmotrimo selektivne analoge ove dvije funkcije.
Neka postoji uzorak skupa vrijednosti neke slučajne varijable volumena  a svaka opcija iz ovog skupa povezana je sa svojom učestalošću. Neka dalje
a svaka opcija iz ovog skupa povezana je sa svojom učestalošću. Neka dalje  je neki realni broj, i
je neki realni broj, i  – broj uzoraka vrijednosti slučajne varijable
– broj uzoraka vrijednosti slučajne varijable  , manji
, manji  .Onda broj
.Onda broj  je učestalost količinskih vrijednosti opaženih u uzorku x, manji
je učestalost količinskih vrijednosti opaženih u uzorku x, manji  ,
oni. učestalost pojavljivanja događaja
,
oni. učestalost pojavljivanja događaja  . Kad se promijeni x u općem slučaju promijenit će se i vrijednost
. Kad se promijeni x u općem slučaju promijenit će se i vrijednost  . To znači da relativna učestalost
. To znači da relativna učestalost  je funkcija argumenta
je funkcija argumenta  . A budući da se ova funkcija nalazi iz uzoraka podataka dobivenih kao rezultat eksperimenata, naziva se selektivna ili empirijski.
. A budući da se ova funkcija nalazi iz uzoraka podataka dobivenih kao rezultat eksperimenata, naziva se selektivna ili empirijski.
Definicija 10.15. Empirijska funkcija distribucije(funkcija distribucije uzorkovanja) je funkcija  , definirajući za svaku vrijednost x relativna učestalost događaja
, definirajući za svaku vrijednost x relativna učestalost događaja  .
.
 (10.19)
(10.19)
Za razliku od funkcije distribucije empirijskog uzorka, funkcija distribucije F(x) opće populacije naziva se teorijska funkcija distribucije. Razlika između njih je u tome što teorijska funkcija F(x)
određuje vjerojatnost događaja  , a empirijski je relativna učestalost istog događaja. Iz Bernoullijevog teorema slijedi
, a empirijski je relativna učestalost istog događaja. Iz Bernoullijevog teorema slijedi
 ,
,
 (10.20)
(10.20)
oni. u cjelini  vjerojatnost
vjerojatnost  i relativna učestalost događaja
i relativna učestalost događaja  , tj.
, tj.  malo razlikuju jedna od druge. Iz ovoga proizlazi da je uputno koristiti empirijsku funkciju distribucije uzorka za aproksimaciju teorijske (integralne) funkcije distribucije opće populacije.
malo razlikuju jedna od druge. Iz ovoga proizlazi da je uputno koristiti empirijsku funkciju distribucije uzorka za aproksimaciju teorijske (integralne) funkcije distribucije opće populacije.
Funkcija  I
I  imaju ista svojstva. To proizlazi iz definicije funkcije.
imaju ista svojstva. To proizlazi iz definicije funkcije. 
Svojstva  :
:

Primjer 10.4. Konstruirajte empirijsku funkciju na temelju dane distribucije uzorka:
|
Mogućnosti | |||
|
Frekvencije |


Riješenje: Pronađimo veličinu uzorka n=
12+18+30=60. Najmanja opcija  , stoga,
, stoga,  na
na  . Značenje
. Značenje  , naime
, naime  promatrano 12 puta, dakle:
promatrano 12 puta, dakle:
 =
= na
na  .
.
Značenje x<
10, naime  I
I  promatrani su 12+18=30 puta, dakle,
promatrani su 12+18=30 puta, dakle,  =
= na
na  . Na
. Na 
 .
.
Tražena empirijska funkcija distribucije:
 =
=
Raspored  prikazano na sl. 10.2
prikazano na sl. 10.2
R  je. 10.2
je. 10.2
Kontrolna pitanja
1. Koje glavne probleme rješava matematička statistika? 2. Opća i ogledna populacija? 3. Definirajte veličinu uzorka. 4. Koji se uzorci nazivaju reprezentativnim? 5. Pogreške reprezentativnosti. 6. Osnovne metode uzorkovanja. 7. Pojmovi frekvencije, relativne frekvencije. 8. Pojam statističkih serija. 9. Zapišite Sturgesovu formulu. 10. Formulirajte koncepte raspona uzorka, medijana i modusa. 11. Poligon frekvencija, histogram. 12. Koncept bodovne procjene populacije uzorka. 13. Pristrana i nepristrana bodovna procjena. 14. Formulirajte pojam prosjeka uzorka. 15. Formulirajte pojam varijance uzorka. 16. Formulirajte pojam standardne devijacije uzorka. 17. Formulirajte pojam koeficijenta varijacije uzorka. 18. Formulirajte pojam geometrijske sredine uzorka.
Varijacijski nizovi. Poligon i histogram.
Raspon distribucije- predstavlja uređenu distribuciju jedinica populacije koja se proučava u skupine prema određenom varirajućem obilježju.
Razlikuju se ovisno o karakteristikama na kojima se temelji formiranje serije distribucije atributivni i varijacijski distribucijski redovi:
§ Serije distribucije konstruirane uzlaznim ili silaznim redoslijedom vrijednosti kvantitativne karakteristike nazivaju se varijacijski.
Niz varijacija distribucije sastoji se od dva stupca:
Prvi stupac daje kvantitativne vrijednosti varirajuće karakteristike, koje se nazivaju opcije i označeni su . Diskretna opcija - izražena kao cijeli broj. Opcija intervala kreće se od i do. Ovisno o vrsti opcija, možete konstruirati diskretni ili intervalni niz varijacija.
Drugi stupac sadrži broj određene opcije, izraženo u terminima frekvencija ili učestalosti:
Frekvencije- ovo su apsolutni brojevi koji pokazuju koliko se puta određena vrijednost karakteristike pojavljuje u agregatu, koji označavaju. Zbroj svih frekvencija mora biti jednak broju jedinica u cijeloj populaciji.
Frekvencije() su frekvencije izražene kao postotak ukupnog broja. Zbroj svih frekvencija izražen u postocima mora biti jednak 100% u razlomcima od jedan.
Grafički prikaz serija distribucije
Distribucijske serije vizualno su prikazane pomoću grafičkih slika.
Serije distribucije prikazane su kao:
§ Poligon
§ Histogrami
§ Kumulira
Poligon
Prilikom konstruiranja poligona, vrijednosti varirajuće karakteristike iscrtavaju se na horizontalnoj osi (x-osi), a frekvencije ili frekvencije se iscrtavaju na okomitoj osi (y-osi).
1. Poligon na sl. 6.1 temelji se na podacima iz mikropopisa stanovništva Rusije 1994. godine.

Grafikon
Za konstruiranje histograma, vrijednosti granica intervala naznačene su duž osi apscise i na temelju njih konstruirani su pravokutnici čija je visina proporcionalna frekvencijama (ili frekvencijama).
Na sl. 6.2. prikazuje histogram distribucije ruskog stanovništva 1997. godine po dobnim skupinama.

Sl. 1. Raspodjela ruskog stanovništva po dobnim skupinama
Empirijska funkcija distribucije, svojstva.
Neka je poznata statistička distribucija učestalosti kvantitativnog obilježja X. Označimo s brojem opažanja u kojima je uočena vrijednost obilježja manja od x, a s n ukupni broj opažanja. Očito, relativna učestalost događaja X Empirijska funkcija distribucije (funkcija distribucije uzorkovanja) je funkcija koja za svaku vrijednost x određuje relativnu učestalost događaja X Za razliku od empirijske funkcije distribucije uzorka, funkcija distribucije populacije naziva se teorijska funkcija distribucije. Razlika između ovih funkcija je u tome što teorijska funkcija određuje vjerojatnost događaja X Kako n raste, relativna učestalost događaja X Osnovna svojstva Neka se namjesti elementarni ishod. Tada je funkcija distribucije diskretne distribucije dana sljedećom funkcijom vjerojatnosti: gdje i Matematičko očekivanje ove distribucije je: Stoga je srednja vrijednost uzorka teorijska sredina distribucije uzorka. Slično tome, varijanca uzorka je teorijska varijanca distribucije uzorka. Slučajna varijabla ima binomnu distribuciju: Funkcija distribucije uzorka je nepristrana procjena funkcije distribucije: Varijanca funkcije distribucije uzorka ima oblik: Prema jakom zakonu velikih brojeva, funkcija distribucije uzorka gotovo sigurno konvergira teorijskoj funkciji distribucije: Funkcija distribucije uzorka je asimptotski normalna procjena teorijske funkcije distribucije. Ako tada Prema distribuciji na . Određivanje empirijske funkcije distribucije Neka je $X$ slučajna varijabla. $F(x)$ je funkcija distribucije zadane slučajne varijable. Provest ćemo $n$ eksperimenata na danoj slučajnoj varijabli pod istim uvjetima, neovisno jedan o drugom. U ovom slučaju dobivamo niz vrijednosti $x_1,\ x_2\ $, ... ,$\ x_n$, koji se naziva uzorak. Definicija 1 Svaka vrijednost $x_i$ ($i=1,2\ $, ... ,$ \ n$) naziva se varijanta. Jedna procjena teorijske funkcije distribucije je empirijska funkcija distribucije. Definicija 3 Empirijska funkcija distribucije $F_n(x)$ je funkcija koja za svaku vrijednost $x$ određuje relativnu učestalost događaja $X \ gdje je $n_x$ broj opcija manji od $x$, $n$ je veličina uzorka. Razlika između empirijske funkcije i teorijske je u tome što teorijska funkcija određuje vjerojatnost događaja $X Razmotrimo sada nekoliko osnovnih svojstava funkcije distribucije. Raspon funkcije $F_n\lijevo(x\desno)$ je segment $$. $F_n\lijevo(x\desno)$ je neopadajuća funkcija. $F_n\lijevo(x\desno)$ je lijevo kontinuirana funkcija. $F_n\left(x\right)$ je komadno konstantna funkcija i raste samo u točkama vrijednosti slučajne varijable $X$ Neka $X_1$ bude najmanja, a $X_n$ najveća opcija. Zatim $F_n\lijevo(x\desno)=0$ za $(x\le X)_1$ i $F_n\lijevo(x\desno)=1$ za $x\ge X_n$. Uvedimo teorem koji povezuje teorijsku i empirijsku funkciju. Teorem 1 Neka je $F_n\left(x\right)$ empirijska funkcija distribucije, a $F\left(x\right)$ teorijska funkcija distribucije općeg uzorka. Tada vrijedi jednakost: \[(\mathop(lim)_(n\to \infty ) (|F)_n\lijevo(x\desno)-F\lijevo(x\desno)|=0\ )\] Primjer 1 Neka distribucija uzorkovanja ima sljedeće podatke zabilježene pomoću tablice: Slika 1. Pronađite veličinu uzorka, izradite empirijsku funkciju distribucije i iscrtajte je. Veličina uzorka: $n=5+10+15+20=50$. Prema svojstvu 5, imamo da je za $x\le 1$ $F_n\left(x\right)=0$, a za $x>4$ $F_n\left(x\right)=1$. $x vrijednost $x vrijednost $x vrijednost Tako dobivamo: Slika 2. Slika 3. Primjer 2 Od gradova središnjeg dijela Rusije nasumično je odabrano 20 gradova za koje su dobiveni sljedeći podaci o cijenama javnog prijevoza: 14, 15, 12, 12, 13, 15, 15, 13, 15, 12, 15, 14 , 15, 13 , 13, 12, 12, 15, 14, 14. Napravite empirijsku funkciju distribucije za ovaj uzorak i nacrtajte je. Zapišimo uzorke vrijednosti uzlaznim redoslijedom i izračunajmo učestalost svake vrijednosti. Dobijamo sljedeću tablicu: Slika 4. Veličina uzorka: $n=20$. Prema svojstvu 5, imamo da za $x\le 12$ $F_n\left(x\right)=0$, a za $x>15$ $F_n\left(x\right)=1$. $x vrijednost $x vrijednost $x vrijednost Tako dobivamo: Slika 5. Nacrtajmo empirijsku distribuciju: Slika 6. Izvornost: 92,12 $\%$. Saznajte koja je empirijska formula. U kemiji, EP je najjednostavniji način za opisivanje spoja—u biti popis elemenata koji čine spoj na temelju njihovog postotka. Treba napomenuti da ova jednostavna formula ne opisuje narudžba atoma u spoju, jednostavno označava od kojih se elemenata sastoji. Na primjer: Razumjeti pojam "postotni sastav"."Postotni sastav" odnosi se na postotak svakog pojedinačnog atoma u cijelom dotičnom spoju. Da biste pronašli empirijsku formulu spoja, morate znati postotni sastav spoja. Ako tražite empirijsku formulu za domaću zadaću, najvjerojatnije će biti navedeni postoci. Imajte na umu da ćete se morati baviti gram atomima. Gram atom je određena količina tvari čija je masa jednaka njezinoj atomskoj masi. Da biste pronašli gram atoma, trebate upotrijebiti sljedeću jednadžbu: Postotak elementa u spoju dijeli se s atomskom masom elementa.
Znati pronaći atomske omjere. Kada radite sa spojem, dobit ćete više od jednog grama atoma. Nakon što pronađete sve gram atome svog spoja, pogledajte ih. Kako biste pronašli atomski omjer, morat ćete odabrati najmanju vrijednost gram-atoma koju ste izračunali. Tada ćete morati podijeliti sve gram atome u najmanji gram atom. Na primjer: Shvatite kako pretvoriti vrijednosti atomskog omjera u cijele brojeve. Kada pišete empirijsku formulu, morate koristiti cijele brojeve. To znači da ne možete koristiti brojeve poput 1,33. Nakon što pronađete omjer atoma, trebate pretvoriti razlomke (kao 1,33) u cijele brojeve (kao 3). Da biste to učinili, morate pronaći cijeli broj, množeći svaki broj atomskog omjera kojim ćete dobiti cijele brojeve. Na primjer: - broj elemenata uzorka jednak . Konkretno, ako su svi elementi uzorka različiti, tada
- broj elemenata uzorka jednak . Konkretno, ako su svi elementi uzorka različiti, tada ![]() .
.![]() .
.![]() .
.![]() .
.![]() gotovo sigurno na .
gotovo sigurno na .Svojstva empirijske funkcije distribucije
Primjeri zadataka nalaženja empirijske funkcije distribucije