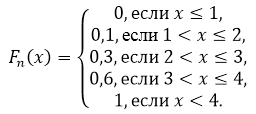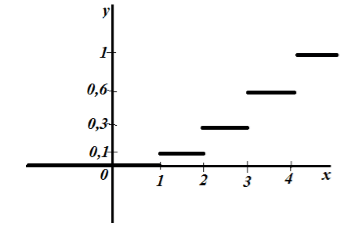Funzione di distribuzione empirica. Funzione di distribuzione empirica, proprietà Esempio di funzione di distribuzione empirica
Lezione 13. Il concetto di stima statistica di variabili casuali
Conosciuta la distribuzione statistica della frequenza di una caratteristica quantitativa X. Indichiamo con il numero di osservazioni in cui il valore della caratteristica è stato osservato inferiore a x e con n il numero totale di osservazioni. Ovviamente, la frequenza relativa dell'evento X< x равна и является функцией x. Так как эта функция находится эмпирическим (опытным) путем, то ее называют эмпирической.
Funzione di distribuzione empirica(funzione di distribuzione campionaria) è una funzione che determina per ciascun valore x la frequenza relativa dell'evento X< x. Таким образом, по определению ,где - число вариант, меньших x, n – объем выборки.
In contrasto con la funzione di distribuzione empirica di un campione, viene chiamata funzione di distribuzione della popolazione funzione di distribuzione teorica. La differenza tra queste funzioni è che la funzione teorica determina probabilità eventi X< x, тогда как эмпирическая – frequenza relativa lo stesso evento.
All’aumentare di n, la frequenza relativa dell’evento X< x, т.е. стремится по вероятности к вероятности этого события. Иными словами
Proprietà della funzione di distribuzione empirica:
1) I valori della funzione empirica appartengono al segmento
2) - funzione non decrescente
3) Se è l'opzione più piccola, allora = 0 per , se è l'opzione più grande, allora = 1 per .
La funzione di distribuzione empirica del campione serve a stimare la funzione di distribuzione teorica della popolazione.
Esempio. Costruiamo una funzione empirica basata sulla distribuzione campionaria:
| Opzioni | |||
| Frequenze |
Troviamo la dimensione del campione: 12+18+30=60. L'opzione più piccola è 2, quindi =0 per x £ 2. Il valore di x<6, т.е. , наблюдалось 12 раз, следовательно, =12/60=0,2 при 2< x £6. Аналогично, значения X < 10, т.е. и наблюдались 12+18=30 раз, поэтому =30/60 =0,5 при 6< x £10. Так как x=10 – наибольшая варианта, то =1 при x>10. Pertanto, la funzione empirica desiderata ha la forma:
Le proprietà più importanti delle stime statistiche
Sia necessario studiare alcune caratteristiche quantitative della popolazione generale. Supponiamo che da considerazioni teoriche sia stato possibile stabilirlo quale esattamente la distribuzione ha segno ed è necessario stimare i parametri con cui viene determinata. Ad esempio, se la caratteristica studiata è distribuita normalmente nella popolazione, allora è necessario stimare l'aspettativa matematica e la deviazione standard; se la caratteristica ha distribuzione di Poisson allora è necessario stimare il parametro l.
In genere, sono disponibili solo dati campione, ad esempio valori di una caratteristica quantitativa ottenuti come risultato di n osservazioni indipendenti. Considerando come variabili casuali indipendenti possiamo dire questo trovare una stima statistica di un parametro sconosciuto di una distribuzione teorica significa trovare una funzione di variabili casuali osservate che dia un valore approssimativo del parametro stimato. Ad esempio, per stimare l'aspettativa matematica di una distribuzione normale, il ruolo della funzione è svolto dalla media aritmetica
Affinché le stime statistiche forniscano corrette approssimazioni dei parametri stimati, esse devono soddisfare alcuni requisiti, tra i quali i più importanti sono quelli non spostato E solvibilità valutazioni.
Sia una stima statistica del parametro sconosciuto della distribuzione teorica. Si trovi la stima a partire da un campione di dimensione n. Ripetiamo l'esperimento, ad es. estraiamo un altro campione della stessa dimensione dalla popolazione generale e, sulla base dei suoi dati, otteniamo una stima diversa. Ripetendo l'esperimento più volte, otteniamo numeri diversi. Il punteggio può essere pensato come una variabile casuale e i numeri come i suoi possibili valori.
Se la stima dà un valore approssimativo in abbondanza, cioè. ogni numero è maggiore del valore reale e, di conseguenza, l'aspettativa matematica (valore medio) della variabile casuale è maggiore di:. Allo stesso modo, se fornisce una stima con uno svantaggio, Quello .
Pertanto, l'utilizzo di una stima statistica, la cui aspettativa matematica non è uguale al parametro stimato, porterebbe a errori sistematici (dello stesso segno). Se, al contrario, ciò garantisce contro errori sistematici.
Imparziale chiamata stima statistica, la cui aspettativa matematica è uguale al parametro stimato per qualsiasi dimensione del campione.
Spostato si dice stima che non soddisfa questa condizione.
L’imparzialità della stima non garantisce ancora una buona approssimazione del parametro stimato, poiché i possibili valori possono essere molto dispersivo intorno al suo valore medio, cioè la varianza può essere significativa. In questo caso, la stima ricavata dai dati di un campione, ad esempio, può risultare significativamente distante dal valore medio, e quindi dal parametro oggetto di stima.
Efficace è una stima statistica che, per una data dimensione del campione n, ha la minima varianza possibile .
Quando si considerano campioni di grandi dimensioni, sono necessarie stime statistiche solvibilità .
Ricco è detta stima statistica, la quale, poiché n®¥ tende con probabilità al parametro stimato. Ad esempio, se la varianza di una stima imparziale tende a zero come n®¥, allora tale stima risulta coerente.
Come è noto, la legge di distribuzione di una variabile casuale può essere specificata in vari modi. Una variabile casuale discreta può essere specificata utilizzando una serie di distribuzioni o una funzione integrale, mentre una variabile casuale continua può essere specificata utilizzando una funzione integrale o differenziale. Consideriamo analoghi selettivi di queste due funzioni.
Lascia che ci sia un insieme campione di valori di qualche variabile di volume casuale  e ciascuna opzione di questo set è associata alla sua frequenza. Andiamo oltre
e ciascuna opzione di questo set è associata alla sua frequenza. Andiamo oltre  è un numero reale e
è un numero reale e  – numero di valori campionari della variabile casuale
– numero di valori campionari della variabile casuale  , più piccola
, più piccola  .Poi il numero
.Poi il numero  è la frequenza dei valori delle quantità osservati nel campione X, più piccola
è la frequenza dei valori delle quantità osservati nel campione X, più piccola  ,
quelli. frequenza con cui si verifica l’evento
,
quelli. frequenza con cui si verifica l’evento  . Quando cambia X nel caso generale, cambierà anche il valore
. Quando cambia X nel caso generale, cambierà anche il valore  . Ciò significa che la frequenza relativa
. Ciò significa che la frequenza relativa  è una funzione dell'argomento
è una funzione dell'argomento  . E poiché questa funzione viene rilevata dai dati campione ottenuti a seguito di esperimenti, viene chiamata selettiva o empirico.
. E poiché questa funzione viene rilevata dai dati campione ottenuti a seguito di esperimenti, viene chiamata selettiva o empirico.
Definizione 10.15. Funzione di distribuzione empirica(funzione di distribuzione campionaria) è la funzione  , definendo per ciascun valore X frequenza relativa dell'evento
, definendo per ciascun valore X frequenza relativa dell'evento  .
.
 (10.19)
(10.19)
In contrasto con la funzione di distribuzione del campionamento empirico, la funzione di distribuzione F(X) della popolazione generale viene chiamato funzione di distribuzione teorica. La differenza tra loro è che la funzione teorica F(X)
determina la probabilità di un evento  , e quella empirica è la frequenza relativa dello stesso evento. Dal teorema di Bernoulli segue
, e quella empirica è la frequenza relativa dello stesso evento. Dal teorema di Bernoulli segue
 ,
,
 (10.20)
(10.20)
quelli. in generale  probabilità
probabilità  e relativa frequenza dell'evento
e relativa frequenza dell'evento  , cioè.
, cioè.  differiscono poco l'uno dall'altro. Da ciò ne consegue che è consigliabile utilizzare la funzione di distribuzione empirica del campione per approssimare la funzione di distribuzione teorica (integrale) della popolazione generale.
differiscono poco l'uno dall'altro. Da ciò ne consegue che è consigliabile utilizzare la funzione di distribuzione empirica del campione per approssimare la funzione di distribuzione teorica (integrale) della popolazione generale.
Funzione  E
E  hanno le stesse proprietà. Ciò segue dalla definizione della funzione.
hanno le stesse proprietà. Ciò segue dalla definizione della funzione. 
Proprietà  :
:

Esempio 10.4. Costruisci una funzione empirica basata sulla distribuzione campionaria data:
|
Opzioni | |||
|
Frequenze |


Soluzione: Troviamo la dimensione del campione N=
12+18+30=60. Opzione più piccola  , quindi,
, quindi,  A
A  . Senso
. Senso  , vale a dire
, vale a dire  osservato 12 volte, quindi:
osservato 12 volte, quindi:
 =
= A
A  .
.
Senso X<
10, cioè  E
E  sono stati osservati 12+18=30 volte, quindi,
sono stati osservati 12+18=30 volte, quindi,  =
= A
A  . A
. A 
 .
.
La funzione di distribuzione empirica richiesta:
 =
=
Programma  mostrato in Fig. 10.2
mostrato in Fig. 10.2
R  È. 10.2
È. 10.2
Domande di controllo
1. Quali problemi principali risolve la statistica matematica? 2. Popolazione generale e campione? 3. Definire la dimensione del campione. 4. Quali campioni sono detti rappresentativi? 5. Errori di rappresentatività. 6. Metodi fondamentali di campionamento. 7. Concetti di frequenza, frequenza relativa. 8. Il concetto di serie statistica. 9. Annota la formula di Sturges. 10. Formulare i concetti di intervallo campionario, mediana e moda. 11. Poligono di frequenza, istogramma. 12. Il concetto di stima puntuale di una popolazione campione. 13. Stima puntuale parziale e imparziale. 14. Formulare il concetto di media campionaria. 15. Formulare il concetto di varianza campionaria. 16. Formulare il concetto di deviazione standard campionaria. 17. Formulare il concetto di coefficiente di variazione campionario. 18. Formulare il concetto di media geometrica campionaria.
Serie di variazioni. Poligono e istogramma.
Gamma di distribuzione- rappresenta una distribuzione ordinata di unità della popolazione studiata in gruppi secondo una certa caratteristica variabile.
A seconda della caratteristica alla base della formazione delle serie distributive, si distinguono attributivo e variazionale righe di distribuzione:
§ Vengono chiamate serie di distribuzione costruite in ordine crescente o decrescente di valori di una caratteristica quantitativa variazionale.
La serie di variazione della distribuzione è composta da due colonne:
La prima colonna fornisce i valori quantitativi delle caratteristiche variabili, che vengono chiamati opzioni e sono designati. Opzione discreta - espressa come numero intero. L'opzione dell'intervallo varia da e a. A seconda del tipo di opzioni, è possibile costruire una serie di variazioni discrete o intervallate.
La seconda colonna contiene numero di opzioni specifiche, espresso in termini di frequenze o frequenze:
Frequenze- questi sono numeri assoluti, che mostrano il numero di volte in cui un determinato valore di una caratteristica si verifica nell'aggregato, che denota. La somma di tutte le frequenze deve essere uguale al numero di unità dell'intera popolazione.
Frequenze() sono frequenze espresse in percentuale sul totale. La somma di tutte le frequenze espresse in percentuale deve essere pari al 100% in frazioni di uno.
Rappresentazione grafica delle serie di distribuzione
Le serie di distribuzione sono presentate visivamente utilizzando immagini grafiche.
Le serie di distribuzione sono rappresentate come:
§ Poligono
§ Istogrammi
§ Cumula
Poligono
Quando si costruisce un poligono, i valori delle caratteristiche variabili vengono tracciati sull'asse orizzontale (asse x) e le frequenze o frequenze vengono tracciate sull'asse verticale (asse y).
1. Poligono in Fig. 6.1 si basa sui dati del microcensimento della popolazione russa del 1994.

grafico a barre
Per costruire un istogramma, lungo l'asse delle ascisse si indicano i valori dei confini degli intervalli e, sulla base di essi, si costruiscono dei rettangoli, la cui altezza è proporzionale alle frequenze (o frequenze).
Nella fig. 6.2. mostra un istogramma della distribuzione della popolazione russa nel 1997 per fascia di età.

Fig. 1. Distribuzione della popolazione russa per classi di età
Funzione di distribuzione empirica, proprietà.
Conosciuta la distribuzione statistica della frequenza di una caratteristica quantitativa X. Indichiamo con il numero di osservazioni in cui il valore della caratteristica è stato osservato inferiore a x e con n il numero totale di osservazioni. Ovviamente, la frequenza relativa dell'evento X Una funzione di distribuzione empirica (funzione di distribuzione campionaria) è una funzione che determina per ciascun valore x la frequenza relativa dell'evento X A differenza della funzione di distribuzione empirica di un campione, la funzione di distribuzione della popolazione è chiamata funzione di distribuzione teorica. La differenza tra queste funzioni è che la funzione teorica determina la probabilità dell'evento X All’aumentare di n, la frequenza relativa dell’evento X Proprietà di base Sia fissato un risultato elementare. Allora la funzione di distribuzione della distribuzione discreta è data dalla seguente funzione di probabilità: dove e L’aspettativa matematica di questa distribuzione è: Pertanto, la media campionaria è la media teorica della distribuzione campionaria. Allo stesso modo, la varianza campionaria è la varianza teorica di una distribuzione campionaria. La variabile casuale ha una distribuzione binomiale: La funzione di distribuzione campionaria è una stima imparziale della funzione di distribuzione: La varianza della funzione di distribuzione campionaria ha la forma: Secondo la legge forte dei grandi numeri, la funzione di distribuzione campionaria converge quasi certamente alla funzione di distribuzione teorica: La funzione di distribuzione campionaria è una stima asintoticamente normale della funzione di distribuzione teorica. Se poi Secondo la distribuzione in . Determinazione della funzione di distribuzione empirica Sia $X$ una variabile casuale. $F(x)$ è la funzione di distribuzione di una data variabile casuale. Effettueremo esperimenti $n$ su una data variabile casuale nelle stesse condizioni, indipendenti l'uno dall'altro. In questo caso otteniamo una sequenza di valori $x_1,\ x_2\ $, ... ,$\ x_n$, che viene chiamata campione. Definizione 1 Ogni valore $x_i$ ($i=1,2\ $, ... ,$ \ n$) è chiamato variante. Una stima della funzione di distribuzione teorica è la funzione di distribuzione empirica. Definizione 3 Una funzione di distribuzione empirica $F_n(x)$ è una funzione che determina per ogni valore $x$ la frequenza relativa dell'evento $X \ dove $n_x$ è il numero di opzioni inferiori a $x$, $n$ è la dimensione del campione. La differenza tra la funzione empirica e quella teorica è che la funzione teorica determina la probabilità dell'evento $X Consideriamo ora alcune proprietà fondamentali della funzione di distribuzione. L'intervallo della funzione $F_n\left(x\right)$ è il segmento $$. $F_n\left(x\right)$ è una funzione non decrescente. $F_n\left(x\right)$ è una funzione continua a sinistra. $F_n\left(x\right)$ è una funzione costante a tratti e aumenta solo nei punti dei valori della variabile casuale $X$ Sia $X_1$ l'opzione più piccola e $X_n$ quella più grande. Quindi $F_n\left(x\right)=0$ per $(x\le X)_1$ e $F_n\left(x\right)=1$ per $x\ge X_n$. Introduciamo un teorema che collega le funzioni teoriche ed empiriche. Teorema 1 Sia $F_n\left(x\right)$ la funzione di distribuzione empirica e $F\left(x\right)$ la funzione di distribuzione teorica del campione generale. Allora vale l’uguaglianza: \[(\mathop(lim)_(n\to \infty ) (|F)_n\left(x\right)-F\left(x\right)|=0\ )\] Esempio 1 Lasciamo che la distribuzione campionaria abbia i seguenti dati registrati utilizzando una tabella: Immagine 1. Trova la dimensione del campione, crea una funzione di distribuzione empirica e tracciala. Dimensione del campione: $n=5+10+15+20=50$. Per la proprietà 5, abbiamo che per $x\le 1$ $F_n\left(x\right)=0$ e per $x>4$ $F_n\left(x\right)=1$. valore $x valore $x valore $x Otteniamo così: Figura 2. Figura 3. Esempio 2 Sono state selezionate casualmente 20 città tra le città della parte centrale della Russia, per le quali sono stati ottenuti i seguenti dati sulle tariffe dei trasporti pubblici: 14, 15, 12, 12, 13, 15, 15, 13, 15, 12, 15, 14 , 15, 13 , 13, 12, 12, 15, 14, 14. Crea una funzione di distribuzione empirica per questo campione e tracciala. Annotiamo i valori campione in ordine crescente e calcoliamo la frequenza di ciascun valore. Otteniamo la seguente tabella: Figura 4. Dimensione del campione: $n=20$. Per la proprietà 5, abbiamo che per $x\le 12$ $F_n\left(x\right)=0$ e per $x>15$ $F_n\left(x\right)=1$. valore $x valore $x valore $x Otteniamo così: Figura 5. Tracciamo la distribuzione empirica: Figura 6. Originalità: $92,12\%$. Scopri qual è la formula empirica. In chimica, EP è il modo più semplice per descrivere un composto, essenzialmente un elenco degli elementi che compongono un composto, in base alle loro percentuali. Va notato che questa semplice formula non descrive ordine atomi in un composto, indica semplicemente di quali elementi è composto. Per esempio: Comprendi il termine "composizione percentuale"."Composizione percentuale" si riferisce alla percentuale di ciascun singolo atomo nell'intero composto in questione. Per trovare la formula empirica di un composto è necessario conoscere la composizione percentuale del composto. Se stai cercando una formula empirica per i compiti, molto probabilmente verranno fornite delle percentuali. Tieni presente che dovrai occuparti dei grammiatomi. Un grammoatomo è una quantità specifica di una sostanza la cui massa è uguale alla sua massa atomica. Per trovare il grammoatomo, è necessario utilizzare la seguente equazione: La percentuale di un elemento in un composto è divisa per la massa atomica dell'elemento.
Sapere come trovare i rapporti atomici. Quando lavori con un composto, ti ritroverai con più di un grammo atomo. Dopo aver trovato tutti i grammiatomi del tuo composto, guardali. Per trovare il rapporto atomico, dovrai selezionare il valore in grammi-atomo più piccolo che hai calcolato. Quindi dovrai dividere tutti i grammi-atomo nel grammo-atomo più piccolo. Per esempio: Comprendere come convertire i valori del rapporto atomico in numeri interi. Quando scrivi una formula empirica, devi usare numeri interi. Ciò significa che non puoi utilizzare numeri come 1,33. Dopo aver trovato il rapporto tra gli atomi, devi convertire le frazioni (come 1,33) in numeri interi (come 3). Per fare ciò, devi trovare un numero intero, moltiplicando ciascun numero del rapporto atomico per il quale otterrai i numeri interi. Per esempio: - numero di elementi del campione pari a . In particolare, se tutti gli elementi del campione sono diversi, allora
- numero di elementi del campione pari a . In particolare, se tutti gli elementi del campione sono diversi, allora ![]() .
.![]() .
.![]() .
.![]() .
.![]() quasi certamente a .
quasi certamente a .Proprietà della funzione di distribuzione empirica
Esempi di problemi sulla ricerca della funzione di distribuzione empirica