Funzione di distribuzione empirica. Funzione di distribuzione empirica, proprietà La funzione di distribuzione empirica è la funzione f x
Lezione 13. Il concetto di stima statistica di variabili casuali
Sia nota la distribuzione statistica della frequenza di una caratteristica quantitativa X. Indichiamo con il numero di osservazioni in cui il valore della caratteristica è stato osservato inferiore a x e con n il numero totale di osservazioni. Ovviamente, la frequenza relativa dell'evento X< x равна и является функцией x. Так как эта функция находится эмпирическим (опытным) путем, то ее называют эмпирической.
Funzione di distribuzione empirica(funzione di distribuzione campionaria) è una funzione che determina per ciascun valore x la frequenza relativa dell'evento X< x. Таким образом, по определению ,где - число вариант, меньших x, n – объем выборки.
In contrasto con la funzione di distribuzione empirica di un campione, viene chiamata funzione di distribuzione della popolazione funzione di distribuzione teorica. La differenza tra queste funzioni è che la funzione teorica determina probabilità eventi X< x, тогда как эмпирическая – frequenza relativa lo stesso evento.
All’aumentare di n, la frequenza relativa dell’evento X< x, т.е. стремится по вероятности к вероятности этого события. Иными словами
Proprietà della funzione di distribuzione empirica:
1) I valori della funzione empirica appartengono al segmento
2) - funzione non decrescente
3) Se è l'opzione più piccola, allora = 0 per , se è l'opzione più grande, allora = 1 per .
La funzione di distribuzione empirica del campione serve a stimare la funzione di distribuzione teorica della popolazione.
Esempio. Costruiamo una funzione empirica basata sulla distribuzione campionaria:
| Opzioni | |||
| Frequenze |
Troviamo la dimensione del campione: 12+18+30=60. L'opzione più piccola è 2, quindi =0 per x £ 2. Il valore di x<6, т.е. , наблюдалось 12 раз, следовательно, =12/60=0,2 при 2< x £6. Аналогично, значения X < 10, т.е. и наблюдались 12+18=30 раз, поэтому =30/60 =0,5 при 6< x £10. Так как x=10 – наибольшая варианта, то =1 при x>10. Pertanto, la funzione empirica desiderata ha la forma:
Le proprietà più importanti delle stime statistiche
Sia necessario studiare alcune caratteristiche quantitative della popolazione generale. Supponiamo che da considerazioni teoriche sia stato possibile stabilirlo quale esattamente la distribuzione ha un segno ed è necessario valutare i parametri con cui viene determinata. Ad esempio, se la caratteristica studiata è distribuita normalmente nella popolazione, allora è necessario stimare l'aspettativa matematica e la deviazione standard; se la caratteristica ha distribuzione di Poisson allora è necessario stimare il parametro l.
In genere, sono disponibili solo dati campione, ad esempio valori di una caratteristica quantitativa ottenuti come risultato di n osservazioni indipendenti. Considerando come variabili casuali indipendenti possiamo dire questo trovare una stima statistica di un parametro sconosciuto di una distribuzione teorica significa trovare una funzione di variabili casuali osservate che dia un valore approssimativo del parametro stimato. Ad esempio, per stimare l'aspettativa matematica di una distribuzione normale, il ruolo della funzione è svolto dalla media aritmetica
Affinché le stime statistiche forniscano corrette approssimazioni dei parametri stimati, esse devono soddisfare alcuni requisiti, tra i quali i più importanti sono quelli non spostato E solvibilità valutazioni.
Sia una stima statistica del parametro sconosciuto della distribuzione teorica. Si trovi la stima a partire da un campione di dimensione n. Ripetiamo l'esperimento, ad es. estraiamo un altro campione della stessa dimensione dalla popolazione generale e, sulla base dei suoi dati, otteniamo una stima diversa. Ripetendo l'esperimento più volte, otteniamo numeri diversi. Il punteggio può essere pensato come una variabile casuale e i numeri come i suoi possibili valori.
Se la stima dà un valore approssimativo in abbondanza, cioè. ogni numero è maggiore del valore reale e, di conseguenza, l'aspettativa matematica (valore medio) della variabile casuale è maggiore di:. Allo stesso modo, se fornisce una stima con uno svantaggio, Quello .
Pertanto, l'utilizzo di una stima statistica, la cui aspettativa matematica non è uguale al parametro stimato, porterebbe a errori sistematici (dello stesso segno). Se, al contrario, ciò garantisce contro errori sistematici.
Imparziale chiamata stima statistica, la cui aspettativa matematica è uguale al parametro stimato per qualsiasi dimensione del campione.
Spostato si dice stima che non soddisfa questa condizione.
L’imparzialità della stima non garantisce ancora una buona approssimazione del parametro stimato, poiché i possibili valori possono essere molto dispersivo attorno al suo valore medio, cioè la varianza può essere significativa. In questo caso, la stima ricavata dai dati di un campione, ad esempio, può risultare significativamente distante dal valore medio, e quindi dal parametro oggetto di stima.
Efficace è una stima statistica che, per una data dimensione del campione n, ha la minima varianza possibile .
Quando si considerano campioni di grandi dimensioni, sono necessarie stime statistiche solvibilità .
Ricco è detta stima statistica, la quale, poiché n®¥ tende con probabilità al parametro stimato. Ad esempio, se la varianza di una stima imparziale tende a zero come n®¥, allora tale stima risulta coerente.
Studiamo qualche tratto quantitativo? popolazione generale e si assume che per qualsiasi dimensione del campione sia nota la distribuzione di frequenza di questa caratteristica. Fissando la dimensione del campione a P, denotare con px numero di opzioni inferiore a x. Quindi non è difficile vedere questa relazione njn esprime la frequenza relativa di un evento (?
Questo rapporto dipende da un numero fisso x e, quindi, è una funzione di questa quantità x. Indichiamolo con F*(x).
Definizione 1.10. Funzione F*(x) = -, esprimendo il relativo
frequenza degli eventi (? funzione empirica
distribuzione (funzione di distribuzione campionaria O funzione di distribuzione statistica).
Quindi, per definizione
Ricordiamo che la funzione di distribuzione della caratteristica ?, La popolazione è definita come la probabilità di un evento (?
![]()
e in contrasto con la funzione di distribuzione empirica viene chiamata funzione di distribuzione teorica. Poiché la funzione di distribuzione empirica è la probabilità dello stesso evento, secondo il teorema di Bernoulli (vedi sezione 5.4), con un campione di grandi dimensioni differiscono poco l'uno dall'altro nel senso che
dove e è un numero positivo arbitrariamente piccolo.
La relazione (1.2) mostra che se la funzione di distribuzione teorica è sconosciuta, allora la funzione di distribuzione empirica trovata dal campione può essere utilizzata come stima campionaria. Dalla formula (1.2) segue contemporaneamente che questa stima è coerente (vedi Definizione 2.4).
Commento 1.6. Atteggiamento nJn può anche essere interpretato come condividere quei membri del campione che si trovano a sinistra di un numero fisso x. Lo indicheremo con co^.
Consideriamo ora un esempio di costruzione di una funzione di distribuzione empirica per un campione discreto.
Esempio 1.2. La distribuzione del campione è nota (Tabella 1.7).
Tabella 1.7
|
Opzione X. |
|||||
|
Frequenza IO. |
Costruire la sua funzione di distribuzione empirica.
Innanzitutto, troviamo la dimensione del campione:
Opzione xx- il più piccolo. Ecco perché n x = 0 e F*(x)= 0 a X% 3, allora P z = 6, cioè a sinistra del punto X= 3 ci sono sei valori campione. Quindi, F*(3) = - = 0,12. A sinistra x = 5 situato
mogli nx=5 = 6 + 9= Opzione 15 campioni. Ecco perché Fn(5) = - = 0,3. COSÌ
Come nx=1 = 6 + 9 + 18 = 33, quindi Fn(7) = - = 0,66. Allo stesso modo troviamo
33 + 12 = 45. Pertanto F* (9) = ^ = 0,9.
L'opzione x 5 = 9 è la più grande. Pertanto, per x > 9, l'intero campione si trova a sinistra di questo punto x. Ecco perché nx>9= 50 e F*(x) = -= 1 per x > 9. 50
Pertanto, dai calcoli sopra effettuati, consegue che la funzione empirica desiderata è definita univocamente su tutto l'asse reale, costante a tratti ed ha la forma

Il grafico di questa funzione rappresenta una figura a gradino ed è mostrato in Fig. 1.6. ?

Per quanto riguarda la questione della costruzione di una funzione empirica per campioni continui, questo problema è risolto, in generale, tutt'altro che inequivocabile. Ciò è dovuto al fatto che i valori della funzione empirica possono essere trovati univocamente solo nei punti finali degli intervalli parziali in cui è suddiviso l'intervallo principale contenente la popolazione campionaria. Ma nei punti interni degli intervalli parziali non è definito. In questi punti è ulteriormente determinato da una funzione costante a tratti (vedi l'esempio precedente) o da qualche funzione continua crescente, ad esempio una funzione lineare, cioè Per costruire la funzione di distribuzione empirica, viene utilizzata un'approssimazione lineare.
Esempio 1.3. Secondo la Tabella 1.3, trovare la funzione di distribuzione empirica dei dipendenti dell’impresa per anzianità di servizio.
Per chiarezza, assumiamo che gli intervalli parziali considerati siano chiusi a sinistra e aperti a destra, cioè contengono solo le estremità sinistre. Sia x = 2. Allora evento n 2 = 0 e F*(2)= 0. Se x e (2; 6), allora a questo punto il valore px non è più definito e con esso non è definito il valore della funzione empirica. Ad esempio, se x = 3, dalle condizioni del problema è impossibile determinare il numero di lavoratori con meno di tre anni di esperienza lavorativa, vale a dire non riesco a trovare la frequenza px e quindi F*(x).
Inoltre, ragionando in modo simile, siamo convinti che la funzione richiesta F*(x) assume valori specifici agli estremi sinistri degli intervalli parziali, ad esempio: "6) = 4/100 = 0,04; "10) = 0,12; "14) = 0,24; "18) = 0,59; F*(22) = 0,78; "26) = 0,90"; "30) = 1, ma non è definito nei punti interni degli intervalli parziali. Per risolvere infine il problema, la funzione desiderata nei punti interni degli intervalli parziali è ulteriormente definita da una funzione costante a tratti (Fig. 1.7) o da una funzione crescente continua (Fig. 1.8, dove la funzione empirica desiderata è ulteriormente definita da una funzione lineare). ?

Determinazione della funzione di distribuzione empirica
Sia $X$ una variabile casuale. $F(x)$ è la funzione di distribuzione di una data variabile casuale. Effettueremo esperimenti $n$ su una data variabile casuale nelle stesse condizioni, indipendenti l'uno dall'altro. In questo caso otteniamo una sequenza di valori $x_1,\ x_2\ $, ... ,$\ x_n$, che viene chiamata campione.
Definizione 1
Ogni valore $x_i$ ($i=1,2\ $, ... ,$ \ n$) è chiamato variante.
Una stima della funzione di distribuzione teorica è la funzione di distribuzione empirica.
Definizione 3
Una funzione di distribuzione empirica $F_n(x)$ è una funzione che determina per ogni valore $x$ la frequenza relativa dell'evento $X \
dove $n_x$ è il numero di opzioni inferiori a $x$, $n$ è la dimensione del campione.
La differenza tra la funzione empirica e quella teorica è che la funzione teorica determina la probabilità dell'evento $X
Proprietà della funzione di distribuzione empirica
Consideriamo ora alcune proprietà fondamentali della funzione di distribuzione.
L'intervallo della funzione $F_n\left(x\right)$ è il segmento $$.
$F_n\left(x\right)$ è una funzione non decrescente.
$F_n\left(x\right)$ è una funzione continua sinistra.
$F_n\left(x\right)$ è una funzione costante a tratti e aumenta solo nei punti dei valori della variabile casuale $X$
Sia $X_1$ la variante più piccola e $X_n$ la variante più grande. Quindi $F_n\left(x\right)=0$ per $(x\le X)_1$ e $F_n\left(x\right)=1$ per $x\ge X_n$.
Introduciamo un teorema che collega le funzioni teoriche ed empiriche.
Teorema 1
Sia $F_n\left(x\right)$ la funzione di distribuzione empirica e $F\left(x\right)$ la funzione di distribuzione teorica del campione generale. Allora vale l’uguaglianza:
\[(\mathop(lim)_(n\to \infty ) (|F)_n\left(x\right)-F\left(x\right)|=0\ )\]
Esempi di problemi sulla ricerca della funzione di distribuzione empirica
Esempio 1
Lasciamo che la distribuzione campionaria abbia i seguenti dati registrati utilizzando una tabella:
Immagine 1.
Trova la dimensione del campione, crea una funzione di distribuzione empirica e tracciala.
Dimensione del campione: $n=5+10+15+20=50$.
Per la proprietà 5, abbiamo che per $x\le 1$ $F_n\left(x\right)=0$ e per $x>4$ $F_n\left(x\right)=1$.
valore $x
valore $x
valore $x
Otteniamo così:

Figura 2.
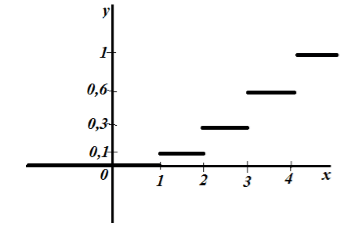
Figura 3.
Esempio 2
Sono state selezionate casualmente 20 città tra le città della parte centrale della Russia, per le quali sono stati ottenuti i seguenti dati sulle tariffe dei trasporti pubblici: 14, 15, 12, 12, 13, 15, 15, 13, 15, 12, 15, 14 , 15, 13 , 13, 12, 12, 15, 14, 14.
Crea una funzione di distribuzione empirica per questo campione e tracciala.
Annotiamo i valori campione in ordine crescente e calcoliamo la frequenza di ciascun valore. Otteniamo la seguente tabella:
Figura 4.
Dimensione del campione: $n=20$.
Per la proprietà 5, abbiamo che per $x\le 12$ $F_n\left(x\right)=0$ e per $x>15$ $F_n\left(x\right)=1$.
valore $x
valore $x
valore $x
Otteniamo così:
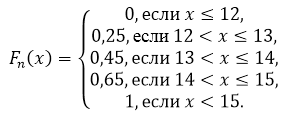
Figura 5.
Tracciamo la distribuzione empirica:

Figura 6.
Originalità: $92,12\%$.
Come è noto, la legge di distribuzione di una variabile casuale può essere specificata in vari modi. Una variabile casuale discreta può essere specificata utilizzando una serie di distribuzioni o una funzione integrale, mentre una variabile casuale continua può essere specificata utilizzando una funzione integrale o differenziale. Consideriamo analoghi selettivi di queste due funzioni.
Lascia che ci sia un insieme campione di valori di qualche variabile di volume casuale  e ciascuna opzione di questo set è associata alla sua frequenza. Andiamo oltre
e ciascuna opzione di questo set è associata alla sua frequenza. Andiamo oltre  è un numero reale e
è un numero reale e  – numero di valori campionari della variabile casuale
– numero di valori campionari della variabile casuale  , più piccola
, più piccola  .Poi il numero
.Poi il numero  è la frequenza dei valori delle quantità osservati nel campione X, più piccola
è la frequenza dei valori delle quantità osservati nel campione X, più piccola  ,
quelli. frequenza con cui si verifica l’evento
,
quelli. frequenza con cui si verifica l’evento 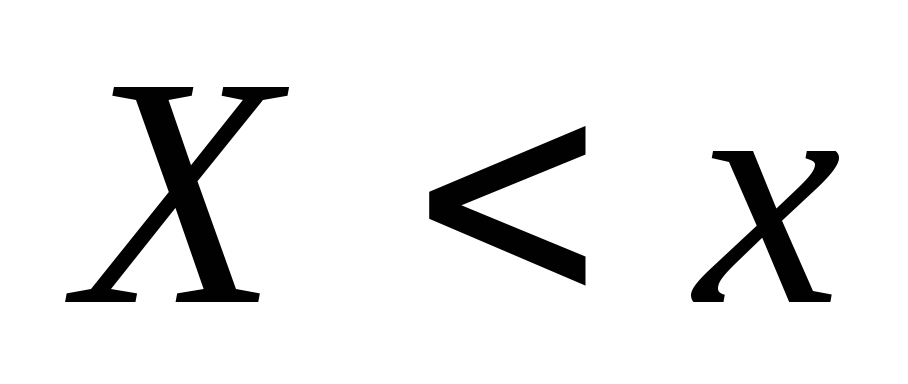 . Quando cambia X nel caso generale cambierà anche il valore
. Quando cambia X nel caso generale cambierà anche il valore  . Ciò significa che la frequenza relativa
. Ciò significa che la frequenza relativa  è una funzione dell'argomento
è una funzione dell'argomento  . E poiché questa funzione viene rilevata dai dati campione ottenuti a seguito di esperimenti, viene chiamata selettiva o empirico.
. E poiché questa funzione viene rilevata dai dati campione ottenuti a seguito di esperimenti, viene chiamata selettiva o empirico.
Definizione 10.15. Funzione di distribuzione empirica(funzione di distribuzione campionaria) è la funzione  , definendo per ciascun valore X frequenza relativa dell'evento
, definendo per ciascun valore X frequenza relativa dell'evento  .
.
 (10.19)
(10.19)
In contrasto con la funzione di distribuzione del campionamento empirico, la funzione di distribuzione F(X) della popolazione generale viene chiamato funzione di distribuzione teorica. La differenza tra loro è che la funzione teorica F(X)
determina la probabilità di un evento  , e quella empirica è la frequenza relativa dello stesso evento. Dal teorema di Bernoulli segue
, e quella empirica è la frequenza relativa dello stesso evento. Dal teorema di Bernoulli segue
 ,
,
 (10.20)
(10.20)
quelli. in generale  probabilità
probabilità  e relativa frequenza dell'evento
e relativa frequenza dell'evento  , cioè.
, cioè.  differiscono poco l'uno dall'altro. Da ciò ne consegue che è consigliabile utilizzare la funzione di distribuzione empirica del campione per approssimare la funzione di distribuzione teorica (integrale) della popolazione generale.
differiscono poco l'uno dall'altro. Da ciò ne consegue che è consigliabile utilizzare la funzione di distribuzione empirica del campione per approssimare la funzione di distribuzione teorica (integrale) della popolazione generale.
Funzione  E
E  hanno le stesse proprietà. Ciò segue dalla definizione della funzione.
hanno le stesse proprietà. Ciò segue dalla definizione della funzione. 
Proprietà  :
:

Esempio 10.4. Costruisci una funzione empirica basata sulla distribuzione campionaria data:
|
Opzioni | |||
|
Frequenze |


Soluzione: Troviamo la dimensione del campione N=
12+18+30=60. Opzione più piccola  , quindi,
, quindi,  A
A  . Senso
. Senso  , vale a dire
, vale a dire  osservato 12 volte, quindi:
osservato 12 volte, quindi:
 =
= A
A  .
.
Senso X<
10, cioè  E
E  sono stati osservati 12+18=30 volte, quindi,
sono stati osservati 12+18=30 volte, quindi,  =
= A
A  . A
. A 
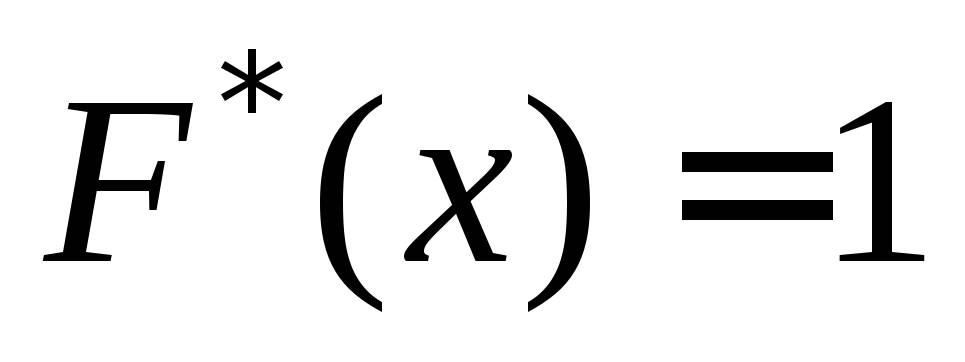 .
.
La funzione di distribuzione empirica richiesta:
 =
=
Programma  mostrato in Fig. 10.2
mostrato in Fig. 10.2
R  È. 10.2
È. 10.2
Domande di controllo
1. Quali problemi principali risolve la statistica matematica? 2. Popolazione generale e campione? 3. Definire la dimensione del campione. 4. Quali campioni sono detti rappresentativi? 5. Errori di rappresentatività. 6. Metodi fondamentali di campionamento. 7. Concetti di frequenza, frequenza relativa. 8. Il concetto di serie statistica. 9. Annota la formula di Sturges. 10. Formulare i concetti di intervallo campionario, mediana e moda. 11. Poligono di frequenza, istogramma. 12. Il concetto di stima puntuale di una popolazione campione. 13. Stima puntuale parziale e imparziale. 14. Formulare il concetto di media campionaria. 15. Formulare il concetto di varianza campionaria. 16. Formulare il concetto di deviazione standard campionaria. 17. Formulare il concetto di coefficiente di variazione campionario. 18. Formulare il concetto di media geometrica campionaria.
Determinazione della funzione di distribuzione empirica
Sia $X$ una variabile casuale. $F(x)$ è la funzione di distribuzione di una data variabile casuale. Effettueremo esperimenti $n$ su una data variabile casuale nelle stesse condizioni, indipendenti l'uno dall'altro. In questo caso otteniamo una sequenza di valori $x_1,\ x_2\ $, ... ,$\ x_n$, che viene chiamata campione.
Definizione 1
Ogni valore $x_i$ ($i=1,2\ $, ... ,$ \ n$) è chiamato variante.
Una stima della funzione di distribuzione teorica è la funzione di distribuzione empirica.
Definizione 3
Una funzione di distribuzione empirica $F_n(x)$ è una funzione che determina per ogni valore $x$ la frequenza relativa dell'evento $X \
dove $n_x$ è il numero di opzioni inferiori a $x$, $n$ è la dimensione del campione.
La differenza tra la funzione empirica e quella teorica è che la funzione teorica determina la probabilità dell'evento $X
Proprietà della funzione di distribuzione empirica
Consideriamo ora alcune proprietà fondamentali della funzione di distribuzione.
L'intervallo della funzione $F_n\left(x\right)$ è il segmento $$.
$F_n\left(x\right)$ è una funzione non decrescente.
$F_n\left(x\right)$ è una funzione continua sinistra.
$F_n\left(x\right)$ è una funzione costante a tratti e aumenta solo nei punti dei valori della variabile casuale $X$
Sia $X_1$ la variante più piccola e $X_n$ la variante più grande. Quindi $F_n\left(x\right)=0$ per $(x\le X)_1$ e $F_n\left(x\right)=1$ per $x\ge X_n$.
Introduciamo un teorema che collega le funzioni teoriche ed empiriche.
Teorema 1
Sia $F_n\left(x\right)$ la funzione di distribuzione empirica e $F\left(x\right)$ la funzione di distribuzione teorica del campione generale. Allora vale l’uguaglianza:
\[(\mathop(lim)_(n\to \infty ) (|F)_n\left(x\right)-F\left(x\right)|=0\ )\]
Esempi di problemi sulla ricerca della funzione di distribuzione empirica
Esempio 1
Lasciamo che la distribuzione campionaria abbia i seguenti dati registrati utilizzando una tabella:
Immagine 1.
Trova la dimensione del campione, crea una funzione di distribuzione empirica e tracciala.
Dimensione del campione: $n=5+10+15+20=50$.
Per la proprietà 5, abbiamo che per $x\le 1$ $F_n\left(x\right)=0$ e per $x>4$ $F_n\left(x\right)=1$.
valore $x
valore $x
valore $x
Otteniamo così:
Figura 2.
Figura 3.
Esempio 2
Sono state selezionate casualmente 20 città tra le città della parte centrale della Russia, per le quali sono stati ottenuti i seguenti dati sulle tariffe dei trasporti pubblici: 14, 15, 12, 12, 13, 15, 15, 13, 15, 12, 15, 14 , 15, 13 , 13, 12, 12, 15, 14, 14.
Crea una funzione di distribuzione empirica per questo campione e tracciala.
Annotiamo i valori campione in ordine crescente e calcoliamo la frequenza di ciascun valore. Otteniamo la seguente tabella:
Figura 4.
Dimensione del campione: $n=20$.
Per la proprietà 5, abbiamo che per $x\le 12$ $F_n\left(x\right)=0$ e per $x>15$ $F_n\left(x\right)=1$.
valore $x
valore $x
valore $x
Otteniamo così:
Figura 5.
Tracciamo la distribuzione empirica:
Figura 6.
Originalità: $92,12\%$.