Dystrybucja empiryczna. Dystrybuanta empiryczna, właściwości Dystrybuantą empiryczną jest funkcja f x
Wykład 13. Pojęcie szacunków statystycznych zmiennych losowych
Niech będzie znany statystyczny rozkład częstości cechy ilościowej X. Oznaczmy przez liczbę obserwacji, w których zaobserwowano wartość cechy mniejszą od x i przez n całkowitą liczbę obserwacji. Oczywiście względna częstotliwość zdarzenia X< x равна и является функцией x. Так как эта функция находится эмпирическим (опытным) путем, то ее называют эмпирической.
Dystrybucja empiryczna(funkcja rozkładu próby) to funkcja, która dla każdej wartości x określa względną częstotliwość zdarzenia X< x. Таким образом, по определению ,где - число вариант, меньших x, n – объем выборки.
W przeciwieństwie do empirycznej funkcji rozkładu próby, funkcję rozkładu populacji nazywa się teoretyczna funkcja dystrybucji. Różnica między tymi funkcjami polega na tym, że określa je funkcja teoretyczna prawdopodobieństwo wydarzenia X< x, тогда как эмпирическая – częstotliwość względna to samo wydarzenie.
Wraz ze wzrostem n względna częstotliwość zdarzenia X< x, т.е. стремится по вероятности к вероятности этого события. Иными словами
Własności dystrybuanty empirycznej:
1) Wartości funkcji empirycznej należą do segmentu
2) - funkcja niemalejąca
3) Jeśli jest najmniejszą opcją, to = 0 dla , jeśli jest największą opcją, to = 1 dla .
Empiryczna funkcja rozkładu próby służy do oszacowania teoretycznej funkcji rozkładu populacji.
Przykład. Skonstruujmy funkcję empiryczną na podstawie rozkładu próby:
| Opcje | |||
| Częstotliwości |
Znajdźmy wielkość próby: 12+18+30=60. Najmniejsza opcja to 2, więc =0 dla x £ 2. Wartość x<6, т.е. , наблюдалось 12 раз, следовательно, =12/60=0,2 при 2< x £6. Аналогично, значения X < 10, т.е. и наблюдались 12+18=30 раз, поэтому =30/60 =0,5 при 6< x £10. Так как x=10 – наибольшая варианта, то =1 при x>10. Zatem pożądana funkcja empiryczna ma postać:
Najważniejsze właściwości szacunków statystycznych
Niech będzie konieczne zbadanie jakiejś ilościowej cechy populacji ogólnej. Załóżmy, że na podstawie rozważań teoretycznych udało się to ustalić który dokładnie rozkład ma znak i konieczne jest oszacowanie parametrów, według których jest wyznaczany. Na przykład, jeśli badana cecha ma rozkład normalny w populacji, konieczne jest oszacowanie oczekiwań matematycznych i odchylenia standardowego; jeżeli cecha ma rozkład Poissona, to należy oszacować parametr l.
Zazwyczaj dostępne są jedynie przykładowe dane, np. wartości cechy ilościowej uzyskane w wyniku n niezależnych obserwacji. Biorąc pod uwagę niezależne zmienne losowe, możemy to powiedzieć znaleźć oszacowanie statystyczne nieznanego parametru rozkładu teoretycznego oznacza znaleźć funkcję obserwowanych zmiennych losowych, która daje przybliżoną wartość szacowanego parametru. Na przykład, aby oszacować matematyczne oczekiwanie rozkładu normalnego, rolę funkcji pełni średnia arytmetyczna
Aby szacunki statystyczne zapewniały prawidłowe przybliżenia szacowanych parametrów, muszą spełniać określone wymagania, spośród których najważniejszymi są wymagania nieprzesunięty I wypłacalność oceny.
Niech będzie statystycznym oszacowaniem nieznanego parametru rozkładu teoretycznego. Niech oszacowanie zostanie znalezione na podstawie próbki o rozmiarze n. Powtórzmy eksperyment, tj. wyodrębnijmy z populacji ogólnej inną próbę o tej samej wielkości i na podstawie jej danych uzyskajmy inny szacunek. Powtarzając eksperyment wielokrotnie, otrzymujemy różne liczby. Wynik można traktować jako zmienną losową, a liczby jako możliwe wartości.
Jeżeli oszacowanie podaje wartość przybliżoną w obfitości, tj. każda liczba jest większa od wartości prawdziwej, w związku z czym oczekiwanie matematyczne (wartość średnia) zmiennej losowej jest większe niż: Podobnie, jeśli podaje szacunkową kwotę z wadą, To .
Zatem zastosowanie oszacowania statystycznego, którego oczekiwanie matematyczne nie jest równe oszacowanemu parametrowi, prowadziłoby do błędów systematycznych (tego samego znaku). Przeciwnie, gwarantuje to uniknięcie błędów systematycznych.
Bezinteresowny zwane oszacowaniem statystycznym, którego matematyczne oczekiwanie jest równe oszacowanemu parametrowi dla dowolnej wielkości próby.
Przesiedlony nazywa się oszacowaniem, które nie spełnia tego warunku.
Bezstronność oszacowania nie gwarantuje jeszcze dobrego przybliżenia szacowanego parametru, ponieważ możliwe wartości można bardzo rozproszone wokół swojej średniej wartości, tj. różnica może być znacząca. W takim przypadku estymacja uzyskana np. z danych jednej próbki może okazać się znacznie odległa od wartości średniej, a co za tym idzie od szacowanego parametru.
Skuteczny jest oszacowaniem statystycznym, które dla danej wielkości próby n ma najmniejsza możliwa różnica .
Rozważając duże próby, wymagane są szacunki statystyczne wypłacalność .
Bogaty nazywa się oszacowaniem statystycznym, które, ponieważ n®¥ zmierza prawdopodobieństwem do szacowanego parametru. Na przykład, jeśli wariancja bezstronnego oszacowania dąży do zera jako n®¥, wówczas takie oszacowanie okazuje się spójne.
Przeanalizujmy jakąś cechę ilościową? populacji ogólnej i założyć, że dla dowolnej wielkości próby znany jest rozkład częstotliwości tej cechy. Ustalając wielkość próbki na P, oznaczać przez p.x liczba opcji mniejsza niż x. Wtedy nietrudno zauważyć tę zależność nie wyraża względną częstotliwość zdarzenia (?
Stosunek ten zależy od ustalonej liczby x i dlatego jest pewną funkcją tej wielkości x. Oznaczmy to przez K*(x).
Definicja 1.10. Funkcjonować F*(x) = -, wyrażając względność
częstotliwość zdarzeń (? funkcja empiryczna
dystrybucja (funkcja rozkładu próbkowania Lub funkcja rozkładu statystycznego).
Zatem z definicji
Przypomnijmy, że funkcja rozkładu cechy ?, populację definiuje się jako prawdopodobieństwo zdarzenia (?
![]()
i w przeciwieństwie do empirycznej funkcji rozkładu tzw teoretyczna funkcja dystrybucji. Ponieważ rozkładem empirycznym jest prawdopodobieństwo tego samego zdarzenia, to zgodnie z twierdzeniem Bernoulliego (patrz podrozdział 5.4) przy dużej liczebności próby różnią się one nieznacznie w tym sensie, że
gdzie e jest dowolną dowolną małą liczbą dodatnią.
Zależność (1.2) pokazuje, że jeśli teoretyczna funkcja rozkładu nie jest znana, to empiryczna funkcja rozkładu znaleziona w próbie może zostać wykorzystana jako oszacowanie próbki. Z wzoru (1.2) wynika jednocześnie, że oszacowanie to jest spójne (patrz Definicja 2.4).
Komentarz 1.6. Postawa nJn można również interpretować jako udział ci członkowie próbki, którzy leżą na lewo od ustalonej liczby x. Oznaczmy to przez co^.
Przyjrzyjmy się teraz przykładowi konstruowania empirycznej funkcji rozkładu dla dyskretnej próbki.
Przykład 1.2. Rozkład próbki jest znany (tabela 1.7).
Tabela 1.7
|
Opcja x. |
|||||
|
Częstotliwość I. |
Skonstruuj jej empiryczną dystrybuantę.
Najpierw znajdźmy wielkość próbki:
Opcja x x- najmniejszy. Dlatego n x = 0 i K*(x)= 0 o godz X Zatem % 3 P z = 6, tj. na lewo od punktu X= 3 istnieje sześć przykładowych wartości. Stąd, F*(3) = - = 0,12. W lewo x = 5 usytuowany
żony nx=5 = 6 + 9= Opcja 15 próbek. Dlatego Fn(5) = - = 0,3. Więc
Jak nx=1 = Zatem 6 + 9 + 18 = 33 Fn(7) = - = 0,66. Podobnie znajdujemy
33 + 12 = 45. Zatem F* (9) = ^ = 0,9.
Opcja x 5 = 9 jest największa. Dlatego dla x > 9 cała próbka leży na lewo od tego punktu x. Dlatego nx>9= 50 i F*(x) = -= 1 dla x > 9, 50
Zatem z przeprowadzonych powyżej obliczeń wynika, że pożądana funkcja empiryczna jest jednoznacznie zdefiniowana na całej osi rzeczywistej, odcinkowo stała i ma postać

Wykres tej funkcji przedstawia liczbę kroków i pokazano na ryc. 1.6. ?

Jeśli chodzi o kwestię konstrukcji funkcji empirycznej dla próbek ciągłych, problem ten, ogólnie rzecz biorąc, nie jest jednoznacznie rozwiązany. Wynika to z faktu, że wartości funkcji empirycznej można jednoznacznie znaleźć jedynie w punktach końcowych przedziałów cząstkowych, na które podzielony jest przedział główny zawierający populację próbną. Ale w wewnętrznych punktach przedziałów cząstkowych nie jest to określone. W tych punktach jest to dalej określane albo przez funkcję stałą odcinkową (patrz poprzedni przykład), albo przez jakąś rosnącą funkcję ciągłą, na przykład funkcję liniową, tj. Do skonstruowania empirycznej funkcji rozkładu stosuje się przybliżenie liniowe.
Przykład 1.3. Zgodnie z tabelą 1.3 znajdź empiryczną dystrybucję pracowników przedsiębiorstwa według stażu pracy.
Dla pewności zakładamy, że rozpatrywane przedziały cząstkowe są domknięte po lewej stronie i otwarte po prawej stronie, tj. zawierają tylko lewe końce. Niech x = 2. Następnie zdarzenie n 2 = 0 i K*(2)= 0. Jeśli x e (2; 6), to w tym momencie wartość p.x nie jest już określona, a wraz z nią nie jest określona wartość funkcji empirycznej. Na przykład, jeśli x = 3, to z warunków problemu nie można określić liczby pracowników z mniej niż trzyletnim stażem pracy, tj. nie mogę znaleźć częstotliwości p.x i dlatego K*(x).
Dalej, rozumując w podobny sposób, jesteśmy przekonani, że wymagana jest funkcja K*(x) przyjmuje określone wartości na lewych końcach przedziałów cząstkowych, na przykład: „6) = 4/100 = 0,04; „10) = 0,12; „14) = 0,24; „18) = 0,59; F*(22) = 0,78; „26) = 0,90”; „30) = 1, ale nie jest ona zdefiniowana w wewnętrznych punktach przedziałów cząstkowych. Aby ostatecznie rozwiązać problem, pożądaną funkcję w wewnętrznych punktach przedziałów cząstkowych definiuje się dalej albo przez funkcję stałą odcinkowo (ryc. 1.7), albo przez pewną funkcję stale rosnącą (ryc. 1.8, gdzie pożądaną funkcję empiryczną definiuje się dalej przez funkcja liniowa). ?

Wyznaczanie empirycznej funkcji rozkładu
Niech $X$ będzie zmienną losową. $F(x)$ jest dystrybuantą danej zmiennej losowej. Eksperymenty $n$ będziemy przeprowadzać na danej zmiennej losowej w tych samych, niezależnych od siebie warunkach. Otrzymujemy w tym przypadku ciąg wartości $x_1,\ x_2\ $, ...,$\ x_n$, który nazywany jest próbką.
Definicja 1
Każda wartość $x_i$ ($i=1,2\ $, ... ,$ \ n$) nazywana jest wariantem.
Jednym z oszacowań teoretycznej funkcji rozkładu jest rozkład empiryczny.
Definicja 3
Dystrybuanta empiryczna $F_n(x)$ jest funkcją wyznaczającą dla każdej wartości $x$ względną częstotliwość zdarzenia $X \
gdzie $n_x$ to liczba opcji mniejsza niż $x$, $n$ to wielkość próby.
Różnica między funkcją empiryczną a teoretyczną polega na tym, że funkcja teoretyczna określa prawdopodobieństwo zdarzenia $X
Własności dystrybuanty empirycznej
Rozważmy teraz kilka podstawowych właściwości funkcji rozkładu.
Zakres funkcji $F_n\left(x\right)$ to segment $$.
$F_n\left(x\right)$ jest funkcją niemalejącą.
$F_n\left(x\right)$ jest funkcją ciągłą lewostronną.
$F_n\left(x\right)$ jest funkcją stałą odcinkowo i rośnie tylko w punktach wartości zmiennej losowej $X$
Niech $X_1$ będzie najmniejszą, a $X_n$ największą opcją. Następnie $F_n\left(x\right)=0$ dla $(x\le X)_1$ i $F_n\left(x\right)=1$ dla $x\ge X_n$.
Wprowadźmy twierdzenie łączące funkcję teoretyczną i empiryczną.
Twierdzenie 1
Niech $F_n\left(x\right)$ będzie dystrybuantą empiryczną, a $F\left(x\right)$ dystrybuantą teoretyczną próby ogólnej. Wtedy zachodzi równość:
\[(\mathop(lim)_(n\to \infty ) (|F)_n\left(x\right)-F\left(x\right)|=0\ )\]
Przykłady problemów ze znalezieniem rozkładu empirycznego
Przykład 1
Niech rozkład próbkowania będzie zawierał następujące dane zapisane za pomocą tabeli:
Obrazek 1.
Znajdź wielkość próby, utwórz empiryczną funkcję rozkładu i wykreśl ją.
Wielkość próbki: $n=5+10+15+20=50$.
Według właściwości 5 mamy to dla $x\le 1$ $F_n\left(x\right)=0$ i dla $x>4$ $F_n\left(x\right)=1$.
Wartość x
Wartość x
Wartość x
W ten sposób otrzymujemy:

Rysunek 2.
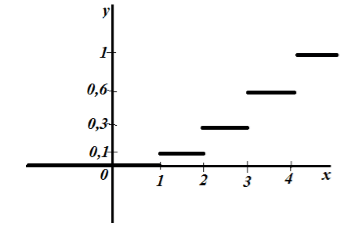
Rysunek 3.
Przykład 2
Spośród miast centralnej części Rosji losowo wybrano 20 miast, dla których uzyskano następujące dane dotyczące opłat za przejazd komunikacją miejską: 14, 15, 12, 12, 13, 15, 15, 13, 15, 12, 15, 14 , 15, 13, 13, 12, 12, 15, 14, 14.
Utwórz empiryczną funkcję rozkładu dla tej próbki i wykreśl ją.
Zapiszmy przykładowe wartości w kolejności rosnącej i obliczmy częstotliwość każdej wartości. Otrzymujemy następującą tabelę:
Rysunek 4.
Wielkość próbki: $n=20$.
Według właściwości 5 mamy to dla $x\le 12$ $F_n\left(x\right)=0$ i dla $x>15$ $F_n\left(x\right)=1$.
Wartość x
Wartość x
Wartość x
W ten sposób otrzymujemy:
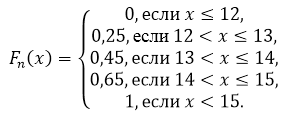
Rysunek 5.
Narysujmy rozkład empiryczny:

Rysunek 6.
Oryginalność: 92,12 $\%$.
Jak wiadomo, prawo rozkładu zmiennej losowej można określić na różne sposoby. Dyskretną zmienną losową można określić za pomocą szeregu rozkładu lub funkcji całkowej, a ciągłą zmienną losową można określić za pomocą funkcji całkowej lub różniczkowej. Rozważmy selektywne analogi tych dwóch funkcji.
Niech będzie przykładowy zestaw wartości jakiejś losowej zmiennej objętości  a każda opcja z tego zbioru jest powiązana z jej częstotliwością. Niech dalej
a każda opcja z tego zbioru jest powiązana z jej częstotliwością. Niech dalej  jest jakąś liczbą rzeczywistą, oraz
jest jakąś liczbą rzeczywistą, oraz  – liczba przykładowych wartości zmiennej losowej
– liczba przykładowych wartości zmiennej losowej  , mniejszy
, mniejszy  .Następnie numer
.Następnie numer  to częstotliwość wartości ilościowych obserwowanych w próbce X, mniejszy
to częstotliwość wartości ilościowych obserwowanych w próbce X, mniejszy  ,
te. częstotliwość występowania zdarzenia
,
te. częstotliwość występowania zdarzenia 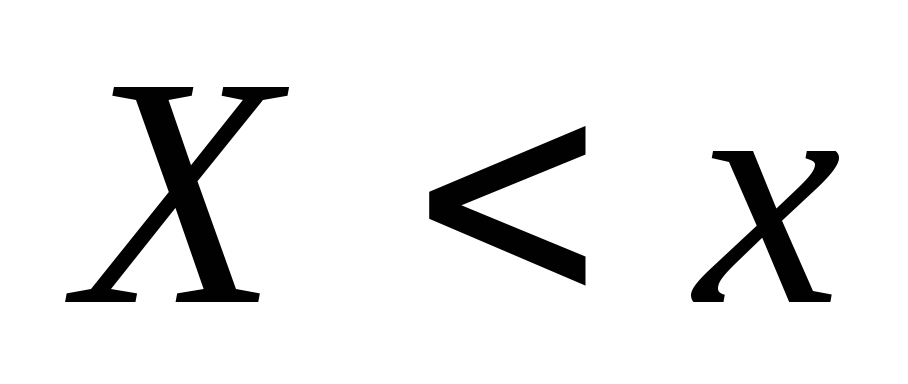 . Kiedy to się zmienia X w ogólnym przypadku wartość również ulegnie zmianie
. Kiedy to się zmienia X w ogólnym przypadku wartość również ulegnie zmianie  . Oznacza to, że częstotliwość względna
. Oznacza to, że częstotliwość względna  jest funkcją argumentu
jest funkcją argumentu  . A ponieważ tę funkcję można znaleźć na podstawie przykładowych danych uzyskanych w wyniku eksperymentów, nazywa się ją selektywną lub empiryczny.
. A ponieważ tę funkcję można znaleźć na podstawie przykładowych danych uzyskanych w wyniku eksperymentów, nazywa się ją selektywną lub empiryczny.
Definicja 10.15. Dystrybucja empiryczna(funkcja rozkładu próby) jest funkcją  , definiując dla każdej wartości X względna częstotliwość zdarzenia
, definiując dla każdej wartości X względna częstotliwość zdarzenia  .
.
 (10.19)
(10.19)
W przeciwieństwie do empirycznej funkcji rozkładu próbkowania, funkcja rozkładu F(X) populacji ogólnej nazywa się teoretyczna funkcja dystrybucji. Różnica między nimi polega na tym, że funkcja teoretyczna F(X)
określa prawdopodobieństwo zdarzenia  , a empiryczny to względna częstotliwość tego samego zdarzenia. Z twierdzenia Bernoulliego wynika
, a empiryczny to względna częstotliwość tego samego zdarzenia. Z twierdzenia Bernoulliego wynika
 ,
,
 (10.20)
(10.20)
te. na wolności  prawdopodobieństwo
prawdopodobieństwo  i względną częstotliwość zdarzenia
i względną częstotliwość zdarzenia  , tj.
, tj.  niewiele się od siebie różnią. Z tego wynika, że wskazane jest wykorzystanie empirycznej funkcji rozkładu próby w celu przybliżenia teoretycznej (całkowej) funkcji rozkładu populacji ogólnej.
niewiele się od siebie różnią. Z tego wynika, że wskazane jest wykorzystanie empirycznej funkcji rozkładu próby w celu przybliżenia teoretycznej (całkowej) funkcji rozkładu populacji ogólnej.
Funkcjonować  I
I  mają te same właściwości. Wynika to z definicji funkcji.
mają te same właściwości. Wynika to z definicji funkcji. 
Nieruchomości  :
:

Przykład 10.4. Skonstruuj funkcję empiryczną na podstawie podanego rozkładu próby:
|
Opcje | |||
|
Częstotliwości |


Rozwiązanie: Znajdźmy wielkość próbki N=
12+18+30=60. Najmniejsza opcja  , stąd,
, stąd,  Na
Na  . Oznaczający
. Oznaczający  , mianowicie
, mianowicie  zaobserwowano 12 razy, zatem:
zaobserwowano 12 razy, zatem:
 =
= Na
Na  .
.
Oznaczający X<
10, a mianowicie  I
I  zaobserwowano 12+18=30 razy, zatem
zaobserwowano 12+18=30 razy, zatem  =
= Na
Na  . Na
. Na 
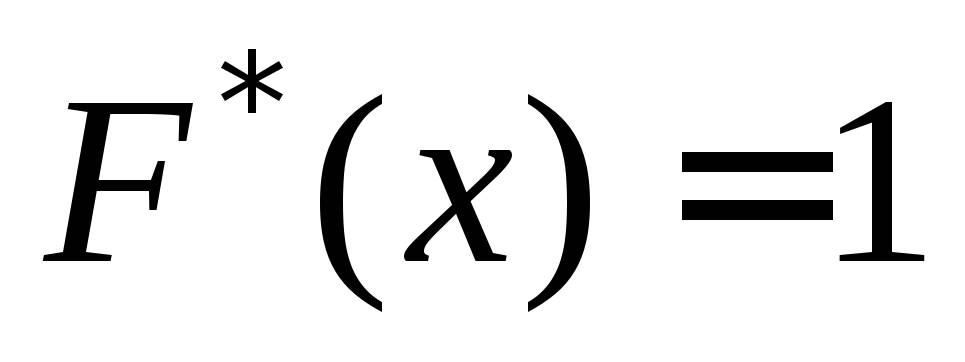 .
.
Wymagana funkcja rozkładu empirycznego:
 =
=
Harmonogram  pokazany na ryc. 10.2
pokazany na ryc. 10.2
R  Jest. 10.2
Jest. 10.2
Pytania kontrolne
1. Jakie główne problemy rozwiązuje statystyka matematyczna? 2. Populacja ogólna i próbna? 3. Określ wielkość próbki. 4. Jakie próbki nazywamy reprezentatywnymi? 5. Błędy reprezentatywności. 6. Podstawowe metody pobierania próbek. 7. Pojęcia częstotliwości, częstotliwość względna. 8. Pojęcie szeregów statystycznych. 9. Zapisz wzór Sturgesa. 10. Formułować pojęcia rozstępu próby, mediany i mody. 11. Wielokąt częstotliwości, histogram. 12. Pojęcie estymaty punktowej populacji próbnej. 13. Nieobciążona i bezstronna estymacja punktowa. 14. Sformułuj pojęcie średniej próbki. 15. Formułować pojęcie wariancji próby. 16. Formułować pojęcie odchylenia standardowego próbki. 17. Formułować pojęcie współczynnika zmienności próbki. 18. Formułować pojęcie średniej geometrycznej próbki.
Wyznaczanie empirycznej funkcji rozkładu
Niech $X$ będzie zmienną losową. $F(x)$ jest dystrybuantą danej zmiennej losowej. Eksperymenty $n$ będziemy przeprowadzać na danej zmiennej losowej w tych samych, niezależnych od siebie warunkach. Otrzymujemy w tym przypadku ciąg wartości $x_1,\ x_2\ $, ...,$\ x_n$, który nazywany jest próbką.
Definicja 1
Każda wartość $x_i$ ($i=1,2\ $, ... ,$ \ n$) nazywana jest wariantem.
Jednym z oszacowań teoretycznej funkcji rozkładu jest rozkład empiryczny.
Definicja 3
Dystrybuanta empiryczna $F_n(x)$ jest funkcją wyznaczającą dla każdej wartości $x$ względną częstotliwość zdarzenia $X \
gdzie $n_x$ to liczba opcji mniejsza niż $x$, $n$ to wielkość próby.
Różnica między funkcją empiryczną a teoretyczną polega na tym, że funkcja teoretyczna określa prawdopodobieństwo zdarzenia $X
Własności dystrybuanty empirycznej
Rozważmy teraz kilka podstawowych właściwości funkcji rozkładu.
Zakres funkcji $F_n\left(x\right)$ to segment $$.
$F_n\left(x\right)$ jest funkcją niemalejącą.
$F_n\left(x\right)$ jest funkcją ciągłą lewostronną.
$F_n\left(x\right)$ jest funkcją stałą odcinkowo i rośnie tylko w punktach wartości zmiennej losowej $X$
Niech $X_1$ będzie najmniejszą, a $X_n$ największą opcją. Następnie $F_n\left(x\right)=0$ dla $(x\le X)_1$ i $F_n\left(x\right)=1$ dla $x\ge X_n$.
Wprowadźmy twierdzenie łączące funkcję teoretyczną i empiryczną.
Twierdzenie 1
Niech $F_n\left(x\right)$ będzie dystrybuantą empiryczną, a $F\left(x\right)$ dystrybuantą teoretyczną próby ogólnej. Wtedy zachodzi równość:
\[(\mathop(lim)_(n\to \infty ) (|F)_n\left(x\right)-F\left(x\right)|=0\ )\]
Przykłady problemów ze znalezieniem rozkładu empirycznego
Przykład 1
Niech rozkład próbkowania będzie zawierał następujące dane zapisane za pomocą tabeli:
Obrazek 1.
Znajdź wielkość próby, utwórz empiryczną funkcję rozkładu i wykreśl ją.
Wielkość próbki: $n=5+10+15+20=50$.
Według właściwości 5 mamy to dla $x\le 1$ $F_n\left(x\right)=0$ i dla $x>4$ $F_n\left(x\right)=1$.
Wartość x
Wartość x
Wartość x
W ten sposób otrzymujemy:
Rysunek 2.
Rysunek 3.
Przykład 2
Spośród miast centralnej części Rosji losowo wybrano 20 miast, dla których uzyskano następujące dane dotyczące opłat za przejazd komunikacją miejską: 14, 15, 12, 12, 13, 15, 15, 13, 15, 12, 15, 14 , 15, 13, 13, 12, 12, 15, 14, 14.
Utwórz empiryczną funkcję rozkładu dla tej próbki i wykreśl ją.
Zapiszmy przykładowe wartości w kolejności rosnącej i obliczmy częstotliwość każdej wartości. Otrzymujemy następującą tabelę:
Rysunek 4.
Wielkość próbki: $n=20$.
Według właściwości 5 mamy to dla $x\le 12$ $F_n\left(x\right)=0$ i dla $x>15$ $F_n\left(x\right)=1$.
Wartość x
Wartość x
Wartość x
W ten sposób otrzymujemy:
Rysunek 5.
Narysujmy rozkład empiryczny:
Rysunek 6.
Oryginalność: 92,12 $\%$.